Приложения для классификации спам сообщений
Проект, темой которого является реализация приложения для классификации спам сообщений. На вход приложение принимает email сообщение полученное через API стороннего сервиса. На выходе получаем список
Описание проекта
Проект, темой которого является реализация приложения для классификации спам сообщений. На вход приложение принимает email сообщение полученное через API стороннего сервиса. На выходе получаем список сообщений, помеченных как спам или не спам.
Бизнес-задача
Разработать и внедрить эффективный детектор спам-сообщений в мессенджере с целью обеспечения безопасности и комфорта пользователей. Задача включает в себя улучшение точности определения спама, минимизацию ложных срабатываний. Результатом должно быть значительное сокращение воздействия нежелательной переписки на пользовательский опыт, повышение доверия к платформе и снижение риска для пользовательской безопасности.
Постановка ML Задачи
Данная задача является задачей обучения с учителем, где есть размеченные данные с информацией о том, является ли сообщение спамом или нет.
Для решения данной задачи требуется:
- собрать набор данных, содержащий примеры спама и нормальных сообщений,
- разделить данные на обучающий, валидационный и тестовый наборы,
- очистить данные от шума, удалить лишние символы или форматирование,
- выбрать модель для классификации текста,
- обучить модель на обучающем наборе данных, используя целевую функцию и оптимизатор,
- оценить производительность модели на валидационном наборе данных, используя метрики, такие как точность, полнота, точность и F1-мера.
Исследование ML-задачи
Существует несколько подходов к реализации детектора спам-сообщений, и выбор зависит от характеристик данных, задачи и доступных ресурсов. Вот несколько основных подходов:
- Правила и эвристики:
- Описание: Основан на наборе правил или эвристик, определяющих характеристики спама (например, ключевые слова, частые символы, ссылки).
- Преимущества: Прост в реализации, требует минимального обучения.
- Недостатки: Может быть неэффективным при появлении новых видов спама, требует постоянного обновления правил.
- Машинное обучение:
- Описание: Использование алгоритмов машинного обучения для автоматического обучения на основе размеченных данных.
- Преимущества: Адаптивен к новым видам спама, способен выявлять сложные паттерны.
- Недостатки: Требует больших объемов размеченных данных и времени для обучения.
- Байесовский классификатор:
- Описание: Использует теорему Байеса для определения вероятности, с которой сообщение является спамом или не спамом.
- Преимущества: Эффективен и относительно прост в реализации.
- Недостатки: Может требовать обновления вероятностей при появлении новых данных.
- Фильтрация на основе правил:
- Описание: Комбинация правил и эвристик для автоматического отсева сообщений согласно определенным критериям.
- Преимущества: Может быть быстрым и эффективным.
- Недостатки: Требует тщательной настройки, может быть менее гибким.
- Глубокое обучение:
- Описание: Использование глубоких нейронных сетей для обучения на данных и выявления сложных зависимостей.
- Преимущества: Способен обрабатывать сложные структуры данных.
- Недостатки: Требует больших объемов данных, вычислительных ресурсов и времени для обучения.
- Комбинированный подход:
- Описание: Использование комбинации нескольких методов для улучшения общей производительности.
- Преимущества: Может объединить преимущества различных подходов.
- Недостатки: Может быть сложным в настройке и управлении.
Исследование датасета
Поиск датасета производился на платформе Hugging Face, с фильтрацией по спам-сообщениям. В результате были найдены 4 датасета с разным объемом и структурой данных. Для каждого датасета был проведен EDA анализ для NLP.
В ходе анализа были получены следующие результаты:
| Характеристика | Датасет | |||
|---|---|---|---|---|
| 33716 строки | 5572 строки | 10900 строки | 20348 строк | |
| Ненулевые строки | 33107 | 5572 | 10900 | 20348 |
| До удаления стоп-слов | ||||
| Средняя длина сообщения | 1489\.83 | 80\.12 | 372\.91 | 326\.84 |
| Минимальная длина сообщения | 1 | 2 | 1 | 1 |
| Максимальная длина сообщения | 228253 | 910 | 41544 | 2584 |
| Количество неуникальных элементов | 3525 | 403 | 238 | 14 |
| Количество уникальных элементов | 29582 | 5169 | 10662 | 20334 |
| Частота униграм | the 288201 to 210184 and 155433 of 146821 in 105450 | to 2242 you 2240 the 1328 and 979 in 898 | the 20275 to 19262 and 17583 you 14606 of 12511 | the 33688 to 31171 and 18672 you 16617 1635465 15636 |
| Частота биграм | of the 30859 in the 24381 hou ect 16212 ect ect 15757 to the 13252 | lt gt 276 are you 180 you are 129 you have 118 do you 109 | looking for 1984 we ve 1663 want to 1555 of the 1543 ve got 1540 | 1635465 1635465 7389 hou ect 3142 of the 2916 ect ect 2772 in the 2534 |
| После удаления стоп-слов | ||||
| Средняя длина сообщения | 1259\.89 | 63\.55 | 294\.17 | 272\.25 |
| Минимальная длина сообщения | 0 | 2 | 1 | 0 |
| Максимальная длина сообщения | 191068 | 579 | 41021 | 2584 |
| Количество неуникальных элементов | 3525 | 404 | 238 | 29 |
| Количество уникальных элементов | 29582 | 5168 | 10662 | 20319 |
| Частота униграм | enron 59775 ect 35338 com 23843 company 22787 please 20102 | call 591 get 391 ur 385 gt 318 lt 316 | data 5840 get 4340 dataset 3257 https 2873 ve 2818 | 1635465 15636 ect 6632 enron 6050 vince 5568 url 4937 |
| Частота биграм | hou ect 16212 ect ect 15764 enron enron 6239 http www 5231 enron com 4417 | lt gt 276 please call 55 call later 50 co uk 49 ll call 45 | ve got 1541 https www 1159 social media 1075 get rich 879 rich quick 836 | 1635465 1635465 7778 hou ect 3142 ect ect 2775 vince kaminski 2522 cc subject 1271 |
График выбросов
Датасет на 33716 строки
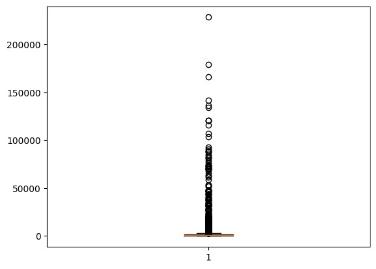
Рисунок 1.До удаления стоп-слов
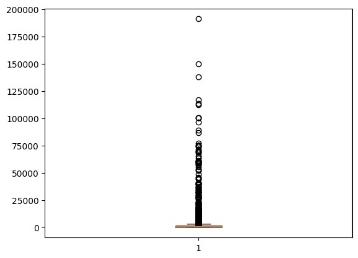
Рисунок 2.После удаления стоп-слов
Датасет на 5572 строки
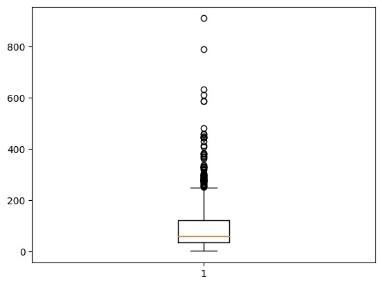
Рисунок 3.До удаления стоп-слов
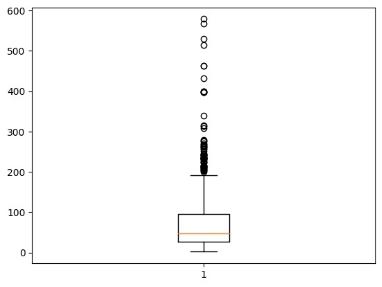
Рисунок 4.После удаления стоп-слов
Датасет на 10900 строк
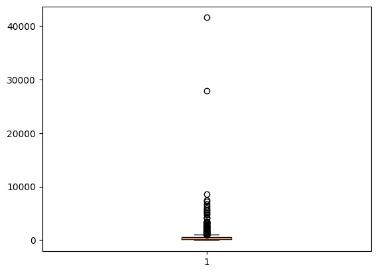
Рисунок 5.До удаления стоп-слов
![]/files/(Aspose.Words.102b1569-64c3-4494-9275-ce75df0f2f3c.006.jpeg)
Рисунок 6.После удаления стоп-слов
Датасет на 20348 строк
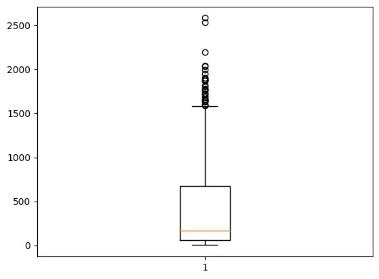
Рисунок 7.До удаления стоп-слов
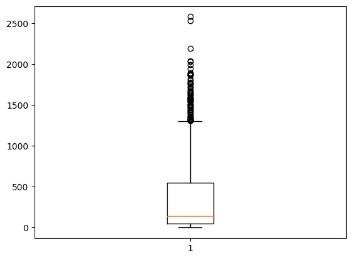
Рисунок 8.После удаления стоп-слов
Исходя из данных, полученных в результате анализа, можно предположить, что датасет на 33716 элементов имеет больше информации для обучения модели.
ML-модели: выбор и сравнение**
Проведено сравнение нескольких моделей для детекции спам-сообщений с использованием данных, сфокусированных на текстовых признаках. Рассмотрим ключевые результаты их производительности:
Рекуррентные Нейронные Сети (RNN)*
Преимущества: - Хорошо учитывает последовательность слов в тексте. - Подходит для обработки долгосрочных зависимостей.
Недостатки: - Требует большого объема данных для эффективного обучения. - Могут возникнуть проблемы с обработкой длинных текстов.
Сверточные Нейронные Сети (CNN)
Преимущества:
- Эффективно обрабатывает локальные паттерны в тексте.
- Обучается быстро на небольших наборах данных.
Недостатки: - Может упускать некоторые последовательные зависимости в тексте.
BERT (Bidirectional Encoder Representations from Transformers)
Преимущества:
- Полностью учитывает контекст и взаимодействие слов в тексте.
- Предоставляет выдающуюся производительность на разнообразных данных.
Недостатки:
- Требует больших вычислительных ресурсов.
- Возможна сложность в fine-tuning на небольших датасетах.
Сравнительный Анализ:
Точность:
BERT показывает наилучшие результаты в точности классификации спама и нормальных сообщений.
Обобщение:
CNN хорошо обобщается на новые данные, несмотря на меньшую точность, что делает ее предпочтительной в сценариях с ограниченными ресурсами.
Скорость обучения:
CNN является наиболее эффективной в обучении на небольших объемах данных, что делает ее более масштабируемой в реальных условиях.
В итоге выбор пал на модель BERT, которая используется для векторизации текста, используемая для обучения модели случайного леса.
Оценка результата
Выбранная модель была обучена на приведенных выше датасетах, каждый из которых был разделен на обучающие и тестовые данные, в соотношении 80/20.
Далее приведены результаты обучения моделей:

Рисунок 9.Датасет на 30к.
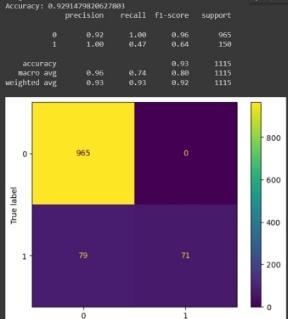
Рисунок 10.Датасет на 5к.
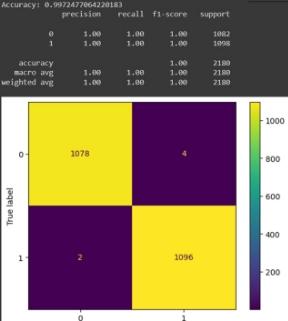
Рисунок 11.Датасет на 10к.
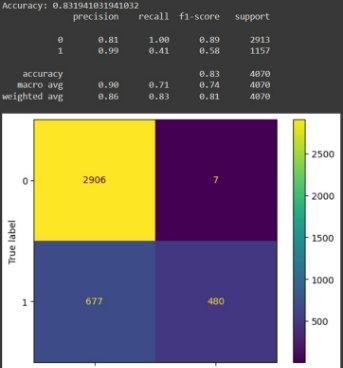
Рисунок 12.Датасет на 20к.
Как можно видеть из рисунков, представленных выше, исходя из оценки f1, лучше всего показывает себя модель обученная на датасете из 30к. элементов. Хуже всего себя показала модель обученная на датасете из 20к. строк, т.к. оценка f1 для нее равна 100%, что демонстрирует плохое качество данных.
**
Архитектура решения
Архитектура системы представлена в виде 3-х уровней диаграммы С4
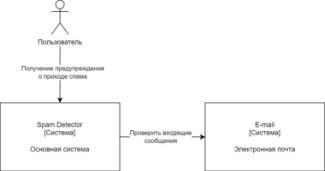
Рисунок 13.Контекстная диаграмма
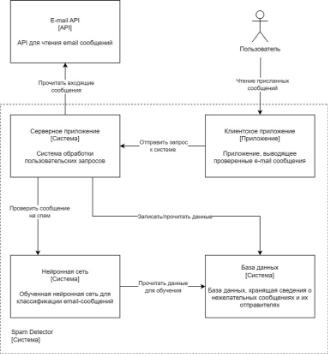
Рисунок 14.Диаграмма контейнеров.
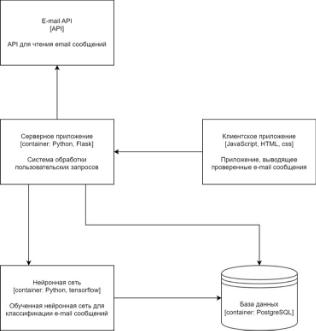
Рисунок 15.Диаграмма компонентов.
Демонстрация решения
В ходе работы было реализовано приложение и интерфейс взаимодействия с ним. Пользователь при входе на сайт может нажать на кнопку “Click_me”, после чего отобразятся все входящие email сообщения с пометкой “spam” или “ham”.

Рисунок 16. Интерфейс приложения с результатами запроса.
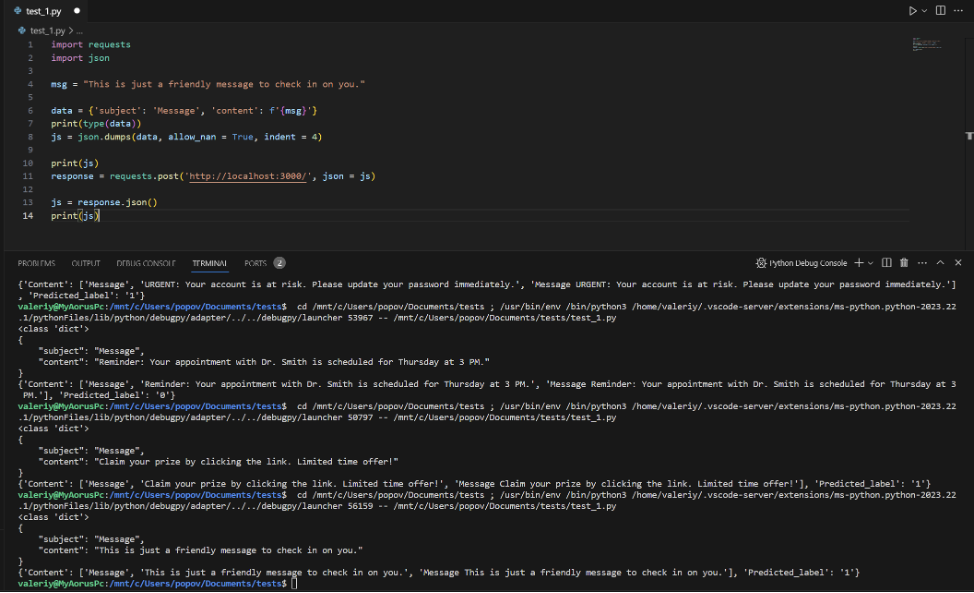
Рисунок 17.Имитация получения email сообщения.
Код приложения расположен в следующем репозитории: - https://github.com/Aloha-dancer/MAIMLPROD
Заключение
В ходе работы было разработано веб-приложение «спам-детектор» для email сообщений, также было проведено исследование задачи, датасета и моделей, подходящих для ее решения, далее была выбрана модель и проведен анализ метрик этой модели , обученной на нескольких датасетах.
Авторы проекта
Студенты группы М8О-206М-22:
- Чирков Артем Андреевич
- Константинов Иван Алексеевич
- Попов Валерий Владиславович
No comments yet. Login to start a new discussion Start a new discussion