Типы инференса ML моделей
Ознакомьтесь с нашим полным руководством по инференсу моделей машинного обучения (ML), охватывающим ключевые аспекты и методы
Инференс (или вывод) в контексте моделей машинного обучения (ML) относится к процессу применения обученной модели к новым данным для получения предсказаний или выводов. Различные типы инференса подходят для разных сценариев использования и требований. Давайте подробнее рассмотрим четыре ключевых типа: Batch Inference, Asynchronous Inference, Serverless Inference и Real-Time Inference.
Batch Inference
Batch Inference — это процесс, при котором модель машинного обучения применяется к большому объему накопленных данных за один раз. В отличие от инференса в реальном времени, пакетный инференс не обрабатывает запросы мгновенно, а скорее выполняет обработку данных в фоновом режиме.
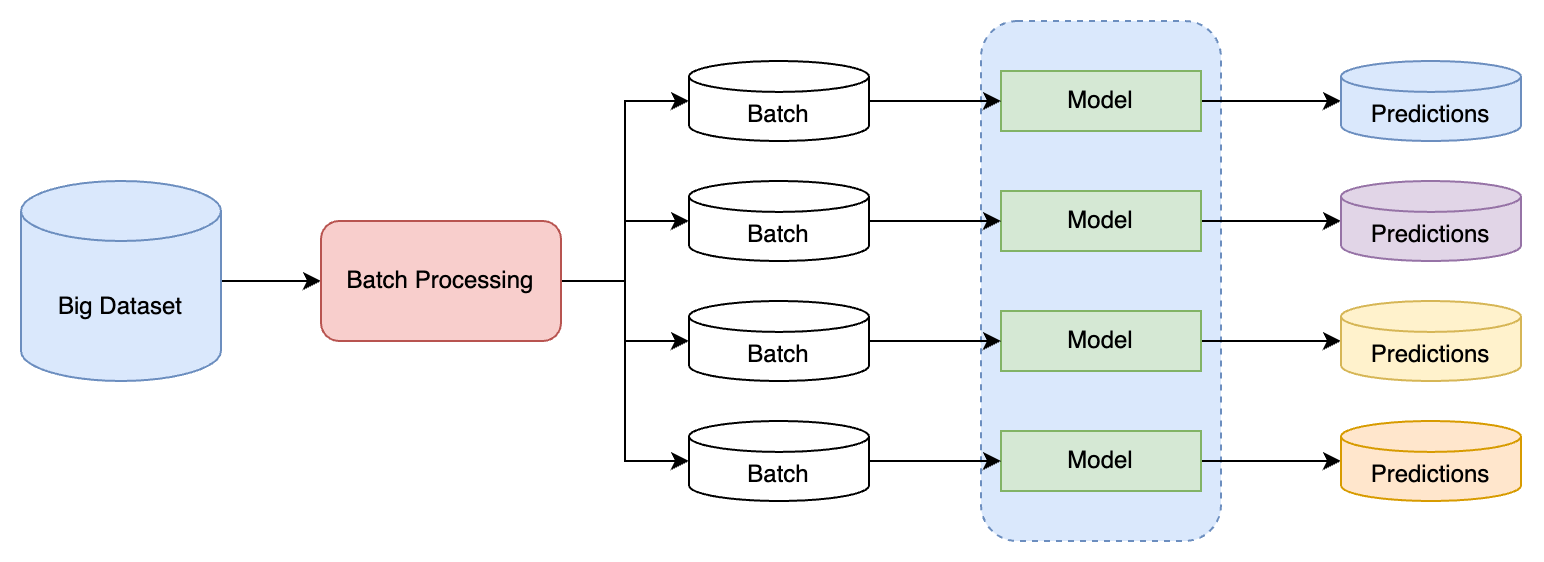
Цели
- Эффективность: Позволяет оптимизировать использование вычислительных ресурсов, обрабатывая большие объемы данных за один подход.
- Масштабируемость: Идеально подходит для сценариев, где данные собираются и обрабатываются в больших масштабах.
- Снижение Стоимости: Минимизирует затраты, поскольку не требует постоянно активных вычислительных ресурсов.
Процесс
- Сбор Данных: Накопление данных до достижения определенного объема или до наступления запланированного времени обработки.
- Предобработка: Подготовка и очистка данных перед подачей в модель.
- Загрузка Модели: Инициализация и загрузка обученной модели ML.
- Инференс: Применение модели ко всему пакету данных.
- Постобработка: Обработка и анализ выводов модели.
- Хранение Результатов: Сохранение или передача результатов для дальнейшего использования.
Типовые Инструменты для Batch Inference
- Apache Spark: Эффективен для обработки больших данных в распределенной среде.
- Amazon S3 и AWS Batch: Обеспечивают хранение данных и управление пакетными задачами в облаке.
- Ray Tasks: Обеспечивает инференс мл модели в распреденном виде
- Python Libraries (Pandas, NumPy): Используются для предобработки данных.
Пример задачи
Задача: Ежедневный анализ большого объема действий пользователя для выявления аномального поведения.
Процесс и Инструменты:
- Сбор действий: Действия собираются в течение дня/недели/месяца и сохраняются в PostgreSQL.
- Предобработка: Использование Apache Spark для очистки и форматирования данных логов.
- Загрузка ML Модели: Модель, обученная с помощью PyTorch и сохраненная на S3, загружается в Spark.
- Batch Inference: Spark применяет модель ко всем логам.
- Постобработка: Результаты анализируются на предмет аномалий.
- Хранение и Отчетность: Результаты сохраняются обратно в ClickHouse, и создается отчет.
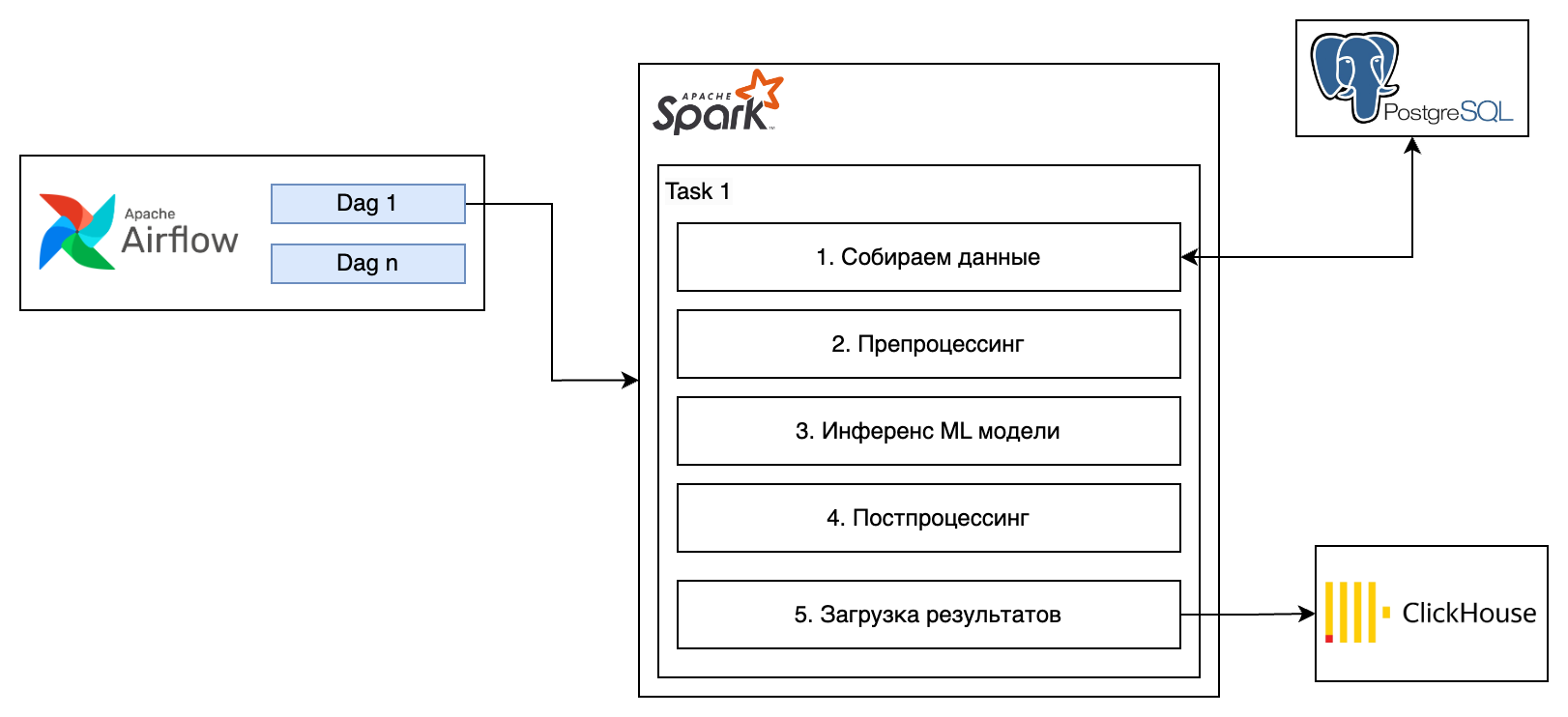
Пример реального сервиса
Пример использования Batch Inference компанией Ozon может быть связан с системой рекомендаций продуктов. В таком сценарии, Batch Inference используется для анализа больших объемов данных покупок пользователей и формирования персонализированных рекомендаций продуктов
Как это работает:
- Сбор Данных:
- Ozon регулярно собирает данные о покупках пользователей, включая информацию о купленных товарах, историю поисковых запросов, отзывы на товары и их рейтинги.
- Данные могут также включать пользовательские профили, предпочтения, историю просмотров и другую релевантную информацию.
- Предобработка Данных:
- Данные очищаются и нормализуются. Например, удаляются дубликаты, исправляются ошибки, преобразуются категориальные данные.
- Обработка Данных:
- В пакетном режиме (Batch Mode) данные обрабатываются моделью машинного обучения. Это может происходить, например, ежедневно в ночное время, когда нагрузка на систему минимальна.
- Модель ML анализирует данные, находя закономерности и связи между покупками и интересами пользователей.
- Генерация Рекомендаций:
- На основе анализа модель формирует персонализированные рекомендации для каждого пользователя.
- Рекомендации могут включать товары, которые могут заинтересовать пользователя на основе его предыдущих покупок и предпочтений.
- Внедрение Рекомендаций:
- Рекомендации интегрируются в пользовательский интерфейс Ozon, так что при следующем визите пользователя на сайт или в приложение, он видит эти персонализированные предложения
Batch Inference представляет собой мощный метод для обработки больших объемов данных, когда время не является критическим фактором. Это позволяет максимально использовать вычислительные ресурсы и подходит для широкого спектра задач аналитики и обработки данных
Asynchronous Inference
Asynchronous Inference (Асинхронный Инференс) в контексте моделей машинного обучения (ML) представляет собой подход, при котором запросы на инференс обрабатываются независимо и не требуют мгновенного ответа. Это позволяет системе обрабатывать другие задачи во время ожидания результата инференса.
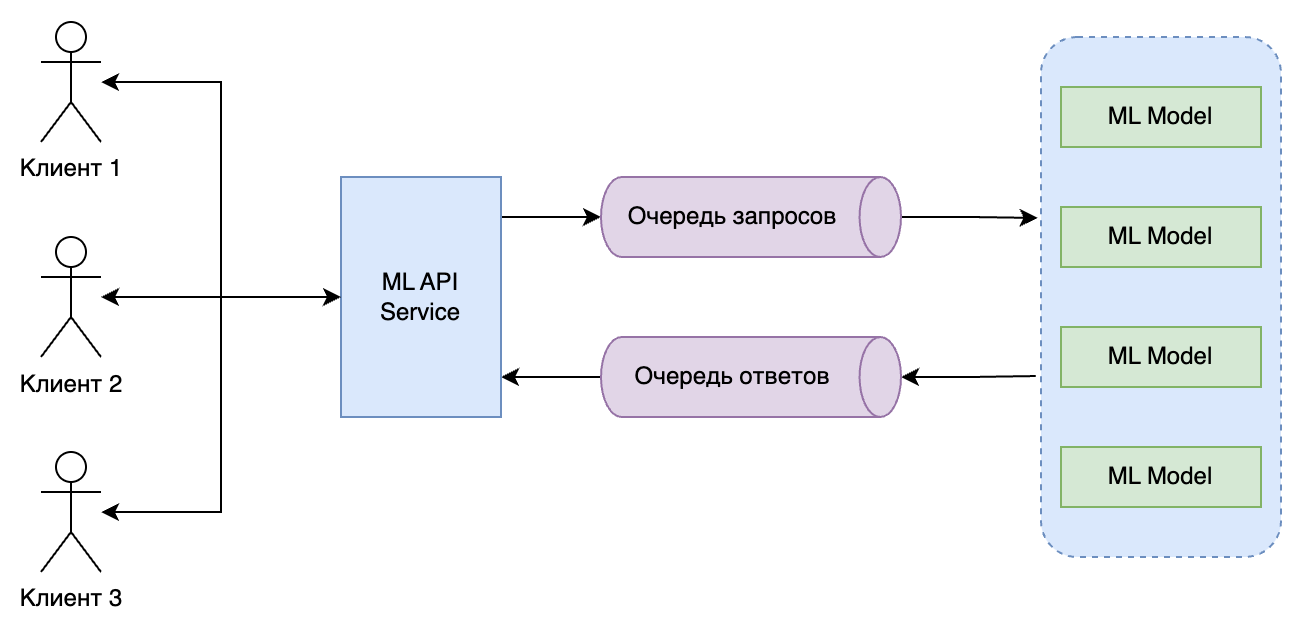
- Описание: Процесс, при котором запросы на инференс отправляются в систему без необходимости немедленного получения ответа. Запросы обрабатываются в фоновом режиме, а результаты могут быть получены позже.
- Цели: Повышение эффективности и масштабируемости системы, снижение нагрузки на вычислительные ресурсы и улучшение управления потоком данных.
Процесс Asynchronous Inference
- Отправка Запроса: Пользователь или приложение отправляет запрос на инференс с данными для обработки.
- Обработка в Фоне: Запрос помещается в очередь и обрабатывается асинхронно.
- Возврат Результата: После обработки запроса результат отправляется обратно пользователю или сохраняется для дальнейшего использования.
Типовые Инструменты для Asynchronous Inference
- Системы Очередей Сообщений: Например, RabbitMQ или Apache Kafka для управления потоком запросов и ответов.
- Фреймворки для Asynchronous Processing: Такие как Celery (Python), которые позволяют управлять задачами и работать с асинхронными запросами.
- Облачные Сервисы: AWS Lambda, Google Cloud Functions для управления асинхронными задачами без необходимости поддержки постоянно работающего сервера.
Пример Задачи
Задача: Генерация изображений с использованием модели глубокого обучения, например, Stable Diffusion, на основе текстовых описаний.
Процесс и Инструменты:
- Отправка Запроса: Пользователь отправляет текстовое описание через Телеграмм Бота, которое помещается в очередь сообщений (например, RabbitMQ).
- Обработка Запроса: Запрос обрабатывается асинхронно с помощью Celery, где модель Stable Diffusion загружается и выполняет инференс.
- Генерация Изображения: Модель обрабатывает текстовое описание и генерирует соответствующее изображение.
- Возврат Результата: Сгенерированное изображение возвращается пользователю через веб-интерфейс или сохраняется для дальнейшего использования.
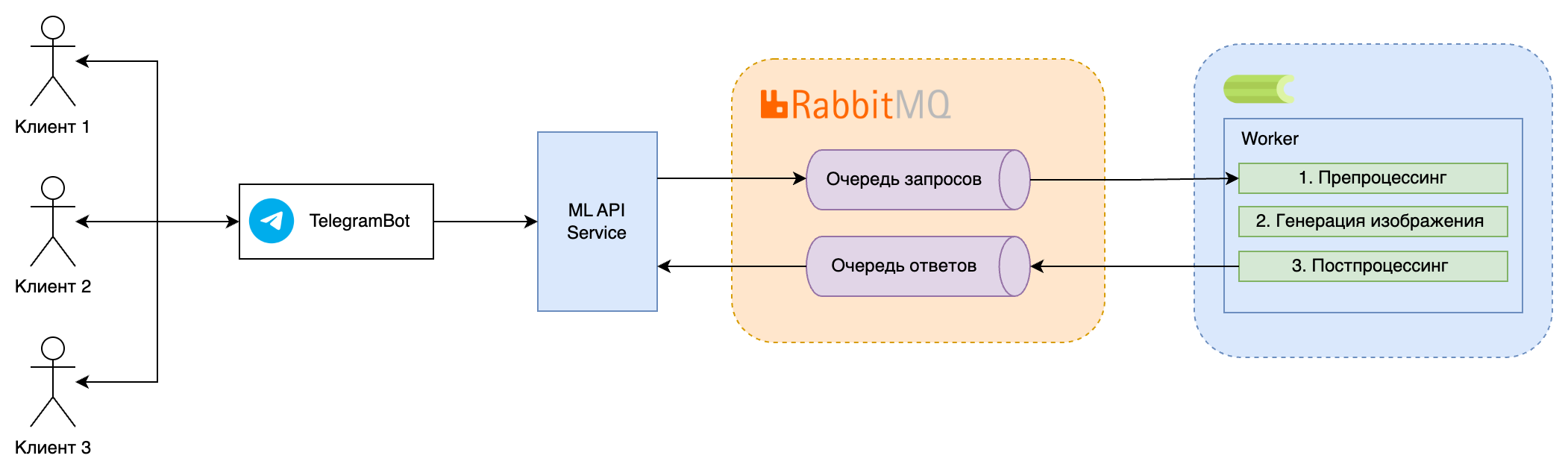
Пример реального сервиса
Пример использования Asynchronous Inference (Асинхронного Инференса) в компании Cloud.ru связан с обработкой пользовательских обращений в службу поддержки. В этом сценарии, асинхронный инференс помогает эффективно обрабатывать большое количество обращений, минимизируя задержки и оптимизируя рабочую нагрузку
Как это работает:
- Получение Обращений:
- Cloud.ruПользователи отправляют обращения в службу поддержки через различные каналы: электронную почту, формы обратной связи на сайте и т.д.
- Каждое обращение содержит текстовое сообщение с описанием проблемы или вопроса пользователя.
- Асинхронная Отправка Запросов:
- Обращения помещаются в систему очередей (например, Apache Kafka), откуда они асинхронно отправляются на обработку.
- Это позволяет системе продолжать принимать новые запросы, не ожидая обработки текущих.
- Обработка Обращений:
- Запросы обрабатываются асинхронно, используя модели машинного обучения для анализа текста и классификации обращений.
- Модели могут определять тип проблемы, срочность, наличие специфических запросов или жалоб.
- Формирование Ответов:
- На основе анализа создаются автоматические ответы или рекомендации для сотрудников поддержки.
- В некоторых случаях система может автоматически предоставлять пользователю базовую информацию или решения стандартных вопросов.
- Отправка Ответов:
- Ответы отправляются пользователям, либо напрямую, либо через операторов поддержки, которые могут дополнительно их отредактировать или расширить.
Асинхронный инференс позволяет эффективно масштабировать ML приложения, обеспечивая высокую производительность и оптимизацию ресурсов, особенно в приложениях, требующих обработки большого количества запросов
Serverless Inference
Serverless Inference (Бессерверный Инференс) в контексте моделей машинного обучения (ML) относится к методу выполнения инференса, при котором не требуется постоянно работающий сервер. Вместо этого вычислительные ресурсы выделяются динамически для обработки каждого запроса на инференс
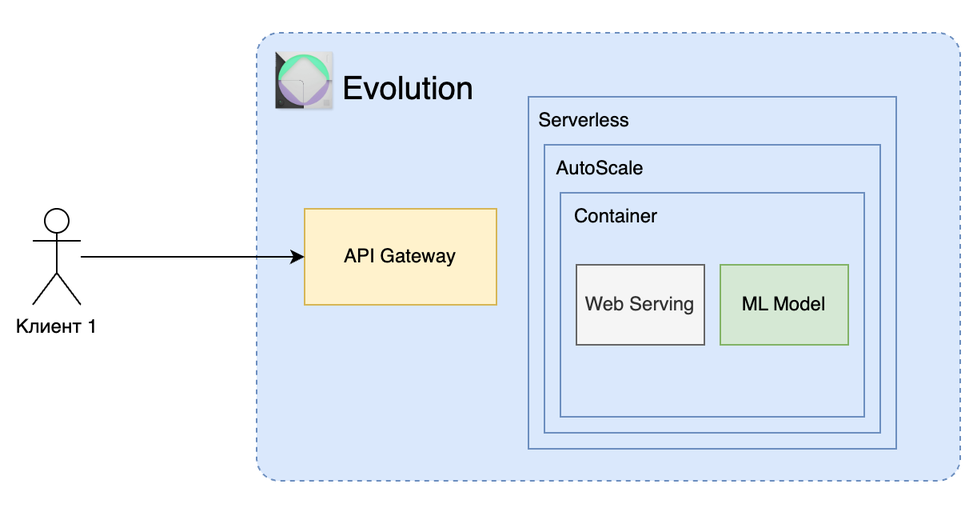
Serverless Inference — это процесс обработки данных моделью ML, при котором вычислительная нагрузка управляется облачной платформой, и пользователь не заботится о поддержке инфраструктуры.
Цели Serverless Inference
- Уменьшение Затрат: Избавление от необходимости поддержки и масштабирования собственной инфраструктуры.
- Эластичность и Масштабируемость: Автоматическое масштабирование ресурсов в соответствии с текущими требованиями к вычислительной мощности.
- Простота Развертывания: Упрощение процесса развертывания моделей ML благодаря использованию облачных услуг.
Процесс Serverless Inference
- Загрузка Модели: Модель ML загружается в облачную среду (например, в Evolution Serverless).
- Настройка Триггеров: Настройка событий, которые будут запускать инференс (например, HTTP-запросы).
- Автоматическое Выполнение: При поступлении запроса на инференс, облачная платформа автоматически выделяет необходимые ресурсы и выполняет инференс.
- Возврат Результата: Результат инференса отправляется обратно клиенту
Типовые Инструменты для Serverless Inference
- AWS Lambda: Позволяет запускать код без управления серверами.
- Google Cloud Functions: Аналогичная платформа от Google.
- Azure Functions: Serverless вычисления от Microsoft.
- Serverless Evolution Cloud.ru: Serverless вычисления от Cloud.ru
- Docker: Для контейнеризации и упаковки моделей ML.
Пример Задачи
Задача: Автоматическое распознавание изображений с использованием модели глубокого обучения.
Процесс и Инструменты:
- Подготовка Модели: Модель PyTorch обучается и экспортируется в формат, совместимый с выбранной облачной платформой.
- Контейнеризация: Модель помещается в Docker-контейнер для упрощения развертывания.
- Загрузка в Serverless Evolution: Контейнер с моделью загружается в Serverless Evolution.
- Настройка API Gateway: Настройка API Gateway в AWS для приема HTTP-запросов на инференс.
- Обработка Запросов: При поступлении запроса с изображением Serverless Evolution автоматически выполняет инференс.
- Возврат Результата: Результаты распознавания отправляются обратно пользователю.
Пример реального сервиса
Пример использования Serverless Inference (Бессерверного Инференса) в компании "Пятерочка" связан с управлением ценообразованием на основе анализа данных о спросе. В этом сценарии, serverless инференс обеспечивает гибкое и масштабируемое решение для анализа больших объемов данных, не требующее постоянного управления серверной инфраструктурой.
- Сбор Данных:
- "Пятерочка" собирает данные о продажах, включая информацию о спросе на различные товары, сезонные изменения, предпочтения покупателей и акционные товары.
- Данные также могут включать внешние факторы, такие как погодные условия или местные события.
- Обработка Данных в Облачной Среде:
- Данные загружаются в облачную платформу, где они доступны для обработки serverless сервисами.
- Используются облачные функции (например, AWS Lambda или Google Cloud Functions) для анализа данных и выполнения инференса модели ML.
- Анализ и Инференс:
- На основе загруженных данных, serverless функции выполняют инференс модели ML для определения оптимальных цен на товары.
- Модель анализирует тренды, спрос и другие факторы, чтобы предложить цены, максимизирующие прибыль и удовлетворение потребностей клиентов.
- Получение Результатов и Применение Изменений:
- Результаты инференса (рекомендации по ценообразованию) отправляются обратно в систему управления "Пятерочки".
- На основе этих данных могут быть внесены изменения в цены товаров в магазинах сети.
Serverless Inference предлагает удобный и экономичный способ запуска ML моделей, особенно полезный для приложений с переменной нагрузкой и требованиями к масштабируемости. Это позволяет разработчикам сосредоточиться на самой модели и ее функциональности, не беспокоясь о поддержке инфраструктуры
Real-Time Inference
Real-Time Inference (Инференс в Реальном Времени) в контексте моделей машинного обучения (ML) относится к быстрой обработке данных и предоставлению результатов в режиме реального времени, что критически важно во многих приложениях, требующих немедленного реагирования.

Real-Time Inference - это процесс, при котором модель ML обрабатывает входящие данные и предоставляет результаты без заметной задержки. Это позволяет использовать модели ML в приложениях, требующих мгновенного реагирования, таких как системы распознавания речи, рекомендательные системы и другие.
Цели Real-Time Inference
- Минимизация Задержек: Обеспечение мгновенного ответа для улучшения пользовательского опыта и эффективности приложений.
- Высокая Производительность: Поддержание стабильной и быстрой работы системы при обработке входящих данных.
- Точность и Надежность: Обеспечение точности и надежности результатов в динамичных условиях.
Процесс Real-Time Inference
- Прием Данных: Непрерывный поток входящих данных, который может поступать от различных источников.
- Обработка Данных: Быстрая предобработка и нормализация данных перед подачей их в модель.
- Загрузка Модели: Использование оптимизированной для быстродействия модели ML.
- Выполнение Инференса: Немедленное применение модели к данным и получение результатов.
- Возврат Результата: Отправка результатов обратно в приложение или систему для дальнейших действий.
Типовые Инструменты для Real-Time Inference
- Фреймворки ML: PyTorch, TensorFlow, особенно их оптимизированные версии для быстрого инференса, например, TensorFlow Lite или PyTorch JIT.
- Серверы Инференса: NVIDIA TensorRT, OpenVINO от Intel для оптимизации производительности на специализированном оборудовании.
- Средства Мониторинга и Оркестрации: Kubernetes, Prometheus для управления и масштабирования ресурсов.
Пример Задачи
Задача: Система распознавания речи для перевода голоса в текст в реальном времени.
Процесс и Инструменты:
- Прием Аудио: Потоковое аудио поступает от пользователя через микрофон.
- Предобработка: Обработка и нормализация аудио сигнала.
- Загрузка Модели: Использование модели распознавания речи, оптимизированной с помощью PyTorch JIT для ускорения инференса.
- Распознавание Речи: Модель обрабатывает аудио и преобразует его в текст в реальном времени.
- Возврат Результата: Текст отправляется обратно в приложение для отображения пользователю.
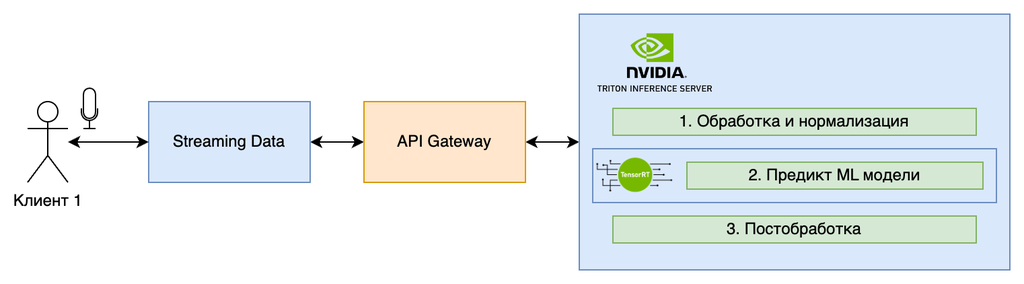
Пример реального сервиса
Пример использования Real-Time Inference (Инференса в Реальном Времени) в сети магазинов "Пятерочка" может быть связан с системой распознавания лиц для идентификации участников программы лояльности и персонализации предложений клиентам при входе в магазин.
Как это работает:
- Установка Камер:
- В магазинах "Пятерочка" устанавливаются камеры с функцией распознавания лиц на входе.
- Эти камеры подключены к системе обработки данных в реальном времени.
- Потоковая Обработка Данных:
- Когда покупатель входит в магазин, камера фиксирует его лицо и отправляет данные на сервер для обработки.
- Сервер использует модель машинного обучения для распознавания лица в реальном времени.
- Идентификация Участника Программы Лояльности:
- Если система распознает лицо как принадлежащее участнику программы лояльности, она немедленно идентифицирует клиента.
- На основе истории покупок и предпочтений клиента система может предложить персонализированные предложения или скидки.
- Персонализация Предложений:
- Система отправляет информацию о клиенте и его предпочтениях на мобильное устройство сотрудника или на специальный терминал.
- Сотрудник магазина или автоматизированная система может предложить клиенту специальные скидки или информацию о продуктах.
Real-Time Inference является ключевым компонентом во многих современных ML приложениях, где скорость и отзывчивость системы имеют решающее значение. Благодаря быстрому инференсу, приложения могут предоставлять пользователю высококачественный и эффективный сервис
Сравнительная таблица
Сравнительная таблица, отображающая плюсы, минусы и цели различных методов инференса моделей машинного обучения
| Тип инференса | Плюсы | Минусы | Цели |
|---|---|---|---|
| Batch Inference | Экономичность, эффективная обработка больших данных. | Высокая задержка, не подходит для реального времени. | Обработка больших наборов данных в нереальном времени. |
| Asynchronous Inference | Улучшение производительности, разгрузка основного потока. | Сложность управления, зависимость от очередей сообщений. | Эффективная обработка множества запросов без блокировки. |
| Serverless Inference | Минимальные затраты на инфраструктуру, эластичность. | Ограничения облачных платформ, холодный старт. | Гибкое и масштабируемое развертывание без управления серверами. |
| Real-Time Inference | Мгновенный ответ, подходит для интерактивных приложений. | Требует значительных вычислительных ресурсов. | Обработка и реагирование на данные в реальном времени. |
Эта таблица поможет определить подходящий метод инференса в зависимости от требований и ограничений конкретного приложения или задачи.
Заключение
В заключение, мы видим, что инференс моделей машинного обучения играет важную роль в различных аспектах бизнеса и предоставляет ценные возможности для улучшения пользовательского опыта и повышения эффективности операций. От пакетной обработки больших данных в Batch Inference до мгновенного реагирования на входящие данные в Real-Time Inference, каждый метод предлагает уникальные преимущества и подходит для определенных сценариев использования.
В компаниях, таких как Ozon, Яндекс, Сбербанк и Пятерочка, мы видим примеры применения этих методов для решения конкретных бизнес-задач: от анализа истории покупок для формирования персонализированных рекомендаций до использования асинхронного инференса для эффективной обработки запросов клиентов. Serverless Inference позволяет оптимизировать процессы, снижая затраты на инфраструктуру и обеспечивая гибкость в обработке данных, в то время как Real-Time Inference открывает двери для инновационных решений, таких как системы распознавания лиц для программ лояльности.
Эти технологии продолжают развиваться, и мы можем ожидать, что будущее принесет еще больше инновационных применений машинного обучения в различных отраслях. Понимание и применение этих методов инференса позволяют компаниям не только повышать эффективность своих операций, но и улучшать взаимодействие с клиентами, предлагая им более качественный и персонализированный сервис
Подписывайтесь на телеграмм канал там больше материла про ML https://t.me/ml_pops
No comments yet. Login to start a new discussion Start a new discussion